DRIFT: A Toolkit for Diachronic Analysis of Scientific Literature
Abstract
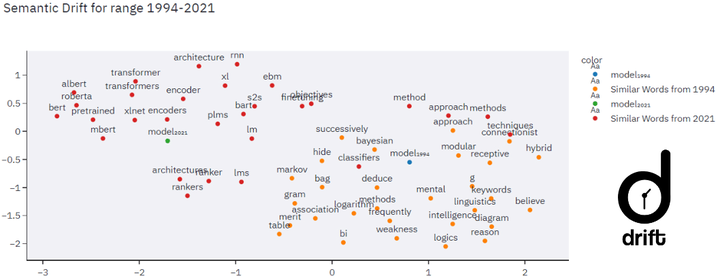
In this work, we present to the NLP community, and to the wider research community as a whole, an application for the diachronic analysis of research corpora. We open source an easy-to-use tool coined: DRIFT, which allows researchers to track research trends and development over the years. The analysis methods are collated from well-cited research works, with a few of our own methods added for good measure. Succinctly put, some of the analysis methods are: keyword extraction, word clouds, predicting declining/stagnant/growing trends using Productivity, tracking bi-grams using Acceleration plots, finding the Semantic Drift of words, tracking trends using similarity, etc. To demonstrate the utility and efficacy of our tool, we perform a case study on the cs.CL corpus of the arXiv repository and draw inferences from the analysis methods. The toolkit and the associated code are available here: https://github.com/rajaswa/DRIFT/.
Harshit Pandey
CDB-FSE Programmer Analyst
My research interests include NLP, adversarial ML and deep learning with domain knowledge.