Multitask Prompted Training Enables Zero-Shot Task Generalization
Abstract
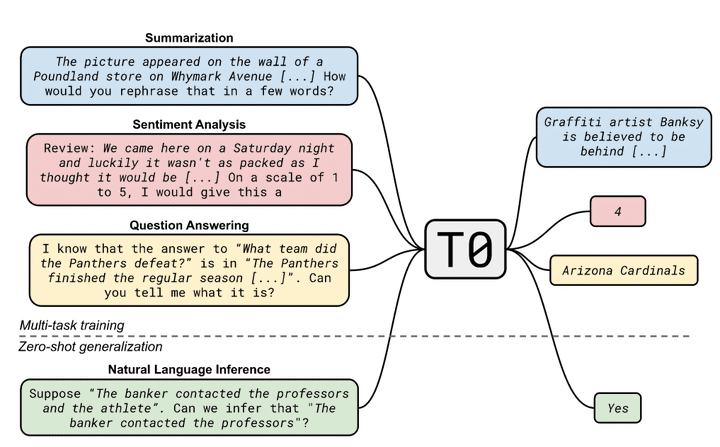
Large language models have recently been shown to attain reasonable zero-shot generalization on a diverse set of tasks (Brown et al., 2020). It has been hypothesized that this is a consequence of implicit multitask learning in language models’ pretraining (Radford et al., 2019). Can zero-shot generalization instead be directly induced by explicit multitask learning? To test this question at scale, we develop a system for easily mapping any natural language tasks into a human-readable prompted form. We convert a large set of supervised datasets, each with multiple prompts with diverse wording. These prompted datasets allow for benchmarking the ability of a model to perform completely unseen tasks. We finetune a pretrained encoder-decoder model (Raffel et al., 2020; Lester et al., 2021) on this multitask mixture covering a wide variety of tasks. The model attains strong zero-shot performance on several standard datasets, often outperforming models up to 16× its size. Further, our approach attains strong performance on a subset of tasks from the BIG-bench benchmark, outperforming models up to 6× its size.
Harshit Pandey
CDB-FSE Programmer Analyst
My research interests include NLP, adversarial ML and deep learning with domain knowledge.