Toxic Spans Detection Leveraging BERT-based Token Classification and Span Prediction Techniques
Abstract
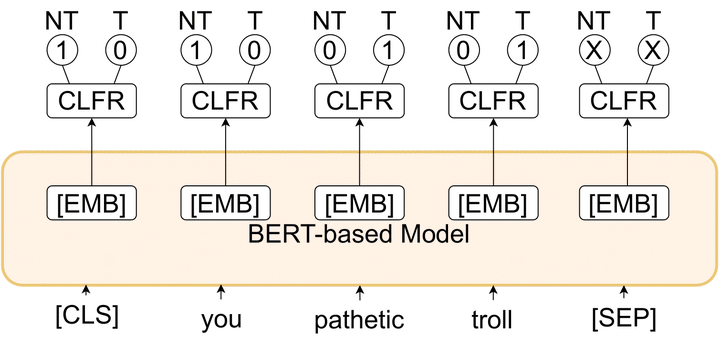
Toxicity detection of text has been a popular NLP task in the recent years. In SemEval-2021 Task-5 Toxic Spans Detection, the focus is on detecting toxic spans within English passages. Most state-of-the-art span detection approaches employ various techniques, each of which can be broadly classified into Token Classification or Span Prediction approaches. In our paper, we explore simple versions of both of these approaches and their performance on the task. Specifically, we use BERT-based models - BERT, RoBERTa, and SpanBERT for both approaches. We also combine these approaches and modify them to bring improvements for Toxic Spans prediction. To this end, we investigate results on four hybrid approaches - Multi-Span, Span+Token, LSTM-CRF, and a combination of predicted offsets using union/intersection. Additionally, we perform a thorough ablative analysis and analyze our observed results. Our best submission - a combination of SpanBERT Span Predictor and RoBERTa Token Classifier predictions - achieves an F1 score of 0.6753 on the test set. Our best post-eval F1 score is 0.6895 on intersection of predicted offsets from top-3 RoBERTa Token Classification checkpoints. These approaches improve the performance by 3% on average than those of the shared baseline models - RNNSL and SpaCy NER.
Harshit Pandey
CDB-FSE Programmer Analyst
My research interests include NLP, adversarial ML and deep learning with domain knowledge.